

weird LLMs, chatbot beige, and new design space
why do all AI products end up being so similar?

Gwern tweet from today got me thinking about weird LLMs.
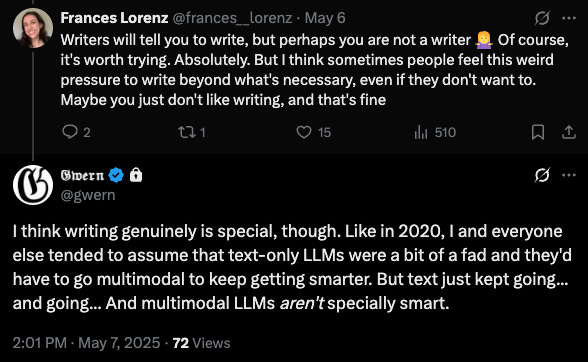
The internet is full of takes on how LLMs are the greatest economic engine since the integrated circuit, so the total lack of weird LLMs is a great mystery to me.
Every single AI product feels like:
ChatGPT for Q&A, search, general utility
Roleplay/social companions
imagegen front ends
therapy
Today I’m asking the question: “where are all the weird LLMs?”
some weird LLM ideas
time-capsule GPT-1971
Imagine a model whose corpus ends on 15 August 1971, the day Nixon suspended gold convertibility and effectively killed Bretton Woods. Its training mix would be period newspapers, Congressional testimony, television transcripts, and technical journals, cleaned but never post-dated. Vocabulary, idioms, and geopolitical priors freeze in amber: the USSR is a permanent fixture, China is “Red China,” and inflation is only just becoming a dinner-table worry. To prevent leakage of modern knowledge, retrieval layers point to scanned microfiche rather than today’s web, and RLHF is done with historians and grumpy old people.
A PhD seminar can interrogate 1971-GPT on Nixon’s wage-price controls, or a novelist can sanity-check dialogue for a period thriller. An optional “parallel-timeline” mode lets modern economists debate the model, then see its counter-reaction from within 1971’s epistemic bubble. Commercialization looks like a time-travel API sold to universities and media, while agentic systems could dispatch 1971-GPT whenever a query includes “historical context,” automatically labeling citations as contemporary to 1971.
hallucination-as-art engine
Instead of punishing hallucinations, this LLM treats them as first-class creative assets. It is fine-tuned with prompts that reward dream logic, surreal metaphors, and synesthetic leaps. A metadata tag—fictional: true—prefaces every answer, freeing models from factual and beige answers while protecting users who need clarity. Stylistic controls let you dial from “mildly whimsical” to “Dalí mode”.
For writers, it becomes a sandbox: pipe an outline in, get plot twists out. The business model mirrors stock-photo libraries—sell dream bundles or license unique story seeds—while safety rests on hard-coded disclaimers and an always-on “reality check” companion model. In agentic stacks, the engine plugs into brainstorming chains: a sober planning agent hands off to Hallucination-GPT for idea explosion, then funnels results back for filtering.
age-tuned companions
The “Kid-GPT” variant speaks at a Grade-3 reading level, uses bright UI colours, and answers the eternal “why?” loop. It is trained on children’s literature and common-core curricula but also embeds strict content filters and parental dashboards. Its elder twin, “Senior-GPT,” features larger fonts, voice-first interaction. Nostalgia is a key driver for utility, so there’s lots of historical context.
Both models tackle engagement loneliness: one keeps eight-year-olds under safe supervision during homework; the other reminds an 82-year-old when to take medication or schedules a Zoom with grandchildren. Monetization could follow the family plan model—one subscription covering multiple age-profiles. There’s value for families in the old-folks version as a pair of ‘eyes’ on how they’re doing (health insurers too, but thats a wee bit dark, right?) . Within agent frameworks, a guardian orchestrator routes requests: chores to mainstream GPT, storytime to Kid-GPT, medication queries to Senior-GPT—ensuring each user talks to a cognitively-aligned persona.
Kids get infinite storybooks where the family cat is the main character, adults get the security of knowing that the model that is creating stories for kids has no knowledge of swearing, violence or stories without morals, and grandma has someone who reminds her to take meds while telling stories of Elvis’ early career days.
values-challenger bot, or change-my-mind bot
Here the system is explicitly tuned to surface contradictions, logical fallacies, and implicit biases in user statements. Training blends debate-club transcripts, philosophy texts, and annotated social-science papers, with a reinforcement signal that rewards respectful disagreement over compliance. The interface telegraphs intent: a prompt might read “Ready to change your mind?” so users opt-in to scrutiny rather than feeling attacked.
Applications range from executive coaching—stress-testing a strategy for blind spots—to classroom debate prep. The model logs bias-heatmaps that visualize which assumptions it flagged, creating a shareable artifact for reflection. A tiered safety scheme prevents it from straying into harassment: tone policing and escalating humility if the user signals discomfort. In multi-agent systems, Challenger-GPT acts as the red-team check on outputs.
deliberate non-engagement model
This LLM is optimized to finish conversations, not extend them. Loss functions penalize token bloat and re-ask rates, while rewards spike for concise, actionable answers. Data for fine-tuning comes from Stack Overflow accepted answers, airline-pilot checklists, and well-rated customer-support macros—sources where brevity equals quality.
The user experience feels like texting a hyper-competent friend: you ask, it replies in 2–4 crisp sentences plus bullet-ready next steps. Business value shows up in call-center AHT (average handle time) reductions and in productivity tools that promise focus, not feed. Because the model bucks engagement metrics, revenue leans on SaaS fees or enterprise licensing, not ads. In agentic workflows, Non-Engagement-GPT becomes the closure node—it cleans up, summarizes, and hands off results to humans or downstream systems, ensuring the chain ends promptly instead of looping forever.
why this doesn’t exist
Big, strange ideas get ironed flat the moment they enter the LLM pipeline. First flattening pass is cost. A single-run post-training bill can still be high 6 figures, and that number covers one try. Boards and investors naturally ask, “Why risk millions on a model that might only serve 1971 economists?” So builders grab an existing generic checkpoint, sprinkle mainstream data on top, and call it done. Even the dataset itself must be flattened—anything with thorny rights is stripped away to avoid lawsuits. By the time the model is trained, there have been dozens of passes of the iron.
Second pass: risk and reputation. Policy teams, brand lawyers, and soon-to-arrive regulators all share a universal incentive—minimize headlines. The cheapest route is rigorous RLHF that penalizes any output deemed controversial, sarcastic, or too weird to explain to a tech journo. “Helpful, harmless, honest” sounds noble; in practice it means sanding off dialect, irony, political edge, and anything else that isnt’ ChatBot Beige. Users end up conversing with an entity as charming as a corporate HR training.
Final pass: metrics and UX. Product managers optimize for CSAT, retention, and net-promoter scores—numbers that spike when conversations stay predictable. Designers stick to the trusty chat because anything funkier tanks onboarding funnels. Meanwhile, copyright and child-safety statutes loom over every pixel, urging teams to remove features that might invite scrutiny. The result: a consumer AI landscape where every stakeholder unconsciously collaborates on the same result—flattening everything interesting into a single, safe, beige, browser chatbot.
maybe it will exist
There’s some evidence that these barriers are falling.
Cost is shrinking; DeepSeek’s sticker price alongside low-cost fine tuning might allow for some experimentation. If you don’t need VC to get weird, thats one less pass of the iron, and I am hopeful.
Risk and Reputation might be easing, too. Sure there’s still going to be safety concerns (and thats good!) but the days of terrible licenses seem to be coming to an end. Regulations have been light, so far, and there should always be space for “experimental model” carve-outs. As more people in the space get funded, there’s more to look into.
“Helpful, Harmless and Designed for Maximum Engagment” might be the hardest to overcome, but there’s cracks in that armour too. Deciding to borrow the FB/YT/Netflix metrics playbook for engagement might have gotten openAi to #5 in traffic worldwide, but the dominance of their product actually may encourage newcos to try new things. I think product teams are noticing. Engagement as the #1 metric might not be the best strategy in 2025.
Finally, agentic architectures might mean that weird LLMs have utility for normie use-cases. Mini models that check bias or give historical perspective might be really useful in orchestrating outcomes that are not about generating text. I hope that there’s a space for eccentric models when we’re orchestrating hundreds of agents in workflows. This might end up producing interesting outcomes.
where to now?
I think there’s room for weird LLMs in the world! If you’re thinking about building something along these lines, reach out, I’d love to talk.